反超OpenAI,百川開源大模型醫療能力登頂世界第一
8月11日,百川智能發布開源醫療增強大模型Baichuan-M2。OpenAI于8月6日開源兩款大模型,主打部署成本超低和醫療能力最強;僅僅5天后,百川開源更小尺寸模型并實現醫療能力反超,在所有開源模型中登頂世界第一。
今年1月,百川在行業內首發“AI患者模擬器”,用真實數據構造上萬個不同年齡性別癥狀的AI患者,模擬了數百萬次診療過程,基于該范式開源的Baichuan-M1,為行業首個醫療增強模型。7個月后,百川升級患者模擬器并引入模型端到端強化學習,訓練的Baichuan-M2在HealthBench等評測上取得更大突破。
OpenAI自2024年下半年起將醫療作為模型能力提升的首要方向,投入大量人力算力精力。今年5月,OpenAI發布權威且貼近真實臨床場景的HealthBench醫療健康評測集,研究團隊招募了262位醫生,來自60個國家、涉及26個醫學專科、精通49種語言,他們生產了48562條評價標準,其中86%是實例特定標準(針對單個對話由醫生撰寫),14%是共識標準。
這個包含了5000個逼真多輪醫療對話的評測集,代表了OpenAI在醫療領域重點突破的決心。開源gpt-oss系列模型過程中,OpenAI首次將醫療作為第一重要的評測標準;發布GPT-5時,請到現場的唯一使用者是抗癌患者,醫療是大模型最有前景最具價值的方向,正成為頭部企業的共識。
Baichuan-M2在HealthBench上得到60.1的高分,以32B的較小尺寸不僅反超OpenAI 最新開源模型gpt-oss120b(得分57.6),更是力壓Qwen3-235B、Deepseek R1、Kimi K2等當前世界所有開源大模型。

針對醫療領域用戶隱私考慮下的模型私有化部署需求,百川智能對Baichuan-M2進行了極致輕量化,量化后的模型精度接近無損,可以在RTX4090上單卡部署,相比DeepSeek-R1 H20雙節點部署的方式,成本降低了57倍。針對國產主流芯片的開發和適配,讓多數醫療機構利用現有硬件條件既可實現快速部署。

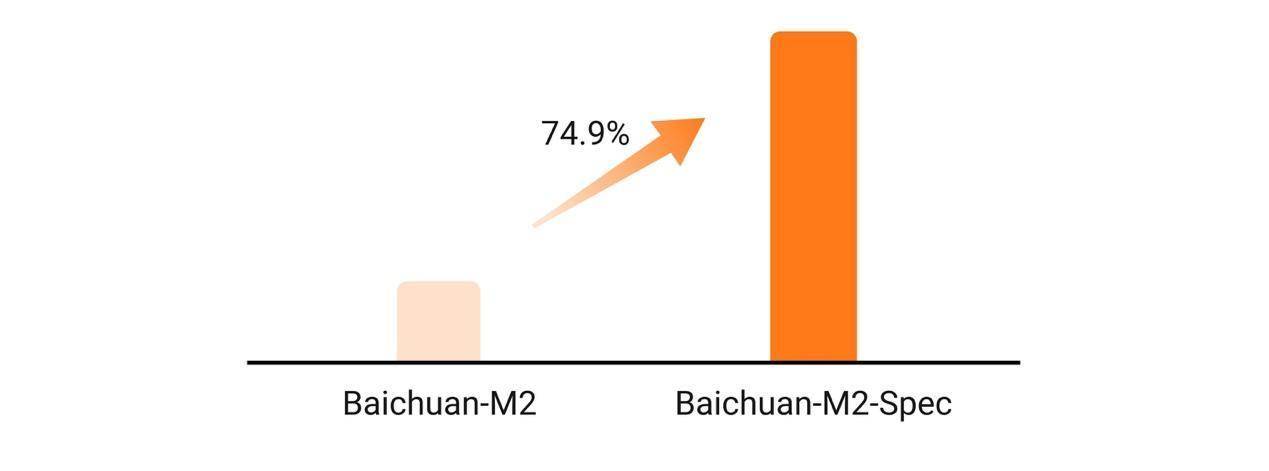
此外,面向急診、門診等對于交互速度要求更高的場景,基于Eagle-3架構優化的Baichuan-M2 MTP版本在單用戶場景下實現了74.9%的token速度躍升。

醫療能力極大增強后,模型通用能力是否會下降?頭部大模型企業主要用數學和代碼數據進行強化學習,百川是首個將醫療數據用作強化學習的中國團隊,同時也驗證了高質量醫療數據對于模型通用能力的增長具有較高價值,M2模型在數學、指令遵循、寫作等通用核心性能上不降反升,因此這個模型也可應用于醫療以外的其他領域。

在大語言模型的發展中,“知識”與“能力”是兩條相輔相成但又相對獨立的主線,模型在醫學考試(如 USMLE)上的表現被視為衡量醫療水平的重要指標,但隨著題庫飽和,這類選擇題或短回復的評測難以反映模型的臨床實用性,醫療 AI 并不等于“刷題機器”,分數再高也不意味著在真實醫療場景中好用。
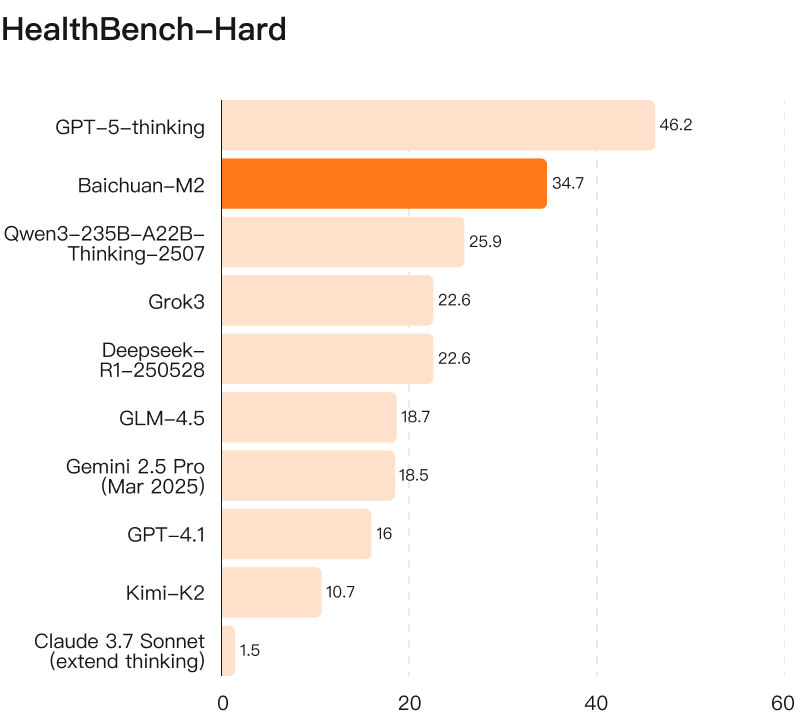
OpenAI從HealthBench整體數據中選出1000個特別困難的復雜問題作為Hard子集,用于驗證模型多維度、全景化解決疑難復雜醫學問題的能力。這個評測方法標準更高、尺度更嚴,更能全面反映模型面臨“千奇百怪”復雜條件時的真實能力。今年5月這個評測集發布時,世界上所有頂尖模型得分都沒超過32分,許多前沿模型得分甚至為0。

Arora R K, Wei J, Hicks R S, et al. Healthbench: Evaluating large language models towards improved human health[J]. arXiv preprint arXiv:2505.08775, 2025.
GPT-5發布時OpenAI特別強調,其是HealthBench Hard評測全球唯一超過32分的模型。Baichuan-M2以34.7分成為全球第二款超過32分的模型,力壓世界所有其他頂尖閉源大模型。
盡管真實醫療場景中還存在大量HealthBench Hard評測尚未包含的因素,但至少已經證明在多數醫療場景上的問答質量,GPT-5和Baichuan-M2已經超越資深醫生,特別是在知識更新速度和全面性上,完全可以給人類醫生強大支持。
GPT-5發布時既沒有開源,也沒有公布參數,無法私有化部署,無法低成本應用。相比之下,Baichuan-M2快速免費開源,成為醫療行業低成本快速應用部署世界頂尖醫療模型的唯一選擇。
百川技術團隊在大型驗證系統(Large Verifier System)、端到端強化學習、AI患者模擬器、多類型醫療數據用于深度推理等4個方面的創新探索,是Baichuan-M2模型取得飛躍式進步的關鍵。
過去一年,可驗證獎勵強化學習(RLVR)方法被頭部大模型企業廣泛使用,在數學、代碼領域顯著提升了模型性能。百川技術團隊在這一過程中認識到,提高復雜現實問題的可驗證性是進一步提升模型性能的關鍵。由此,他們構建了大型驗證系統,在通用驗證器之外還設計了一套全面的醫學驗證系統。
如果將未經過醫療強化學習的大模型比作一位醫學實習生,這個系統則像一個要求極高、異常挑剔的醫療專家。它會從醫療正確性、完備性、安全性以及對患者的友好性等多個維度,細致地評估模型的輸出,指出其不足并引導模型改正,使其思維方式更貼近專業醫生。
在這個強大驗證系統的基礎上,團隊采用多階段強化學習策略(Multi- Stage RL),將復雜的強化學習任務分解為幾個易于管理的、分層的訓練階段,逐步引導模型能力演變。
人類醫生在聽取患者描述病情時,很容易分辨患者描述中的邏輯漏洞、從含混不清的表達中辨別出真實病因。現實中患者幾乎無法全面準確表達自己的癥狀,僅基于靜態的病例、指南等醫療數據訓練,模型無法掌握人類醫生的這一能力。為了突破這一瓶頸,百川技術團隊升級迭代了今年初首創的AI患者模擬器。這個模型器是使用真實病例構建的AI系統,能夠模擬千差萬別的患者、癥狀、表達,特別是包含錯誤噪聲的表達,最大程度還原了真實醫療場景。
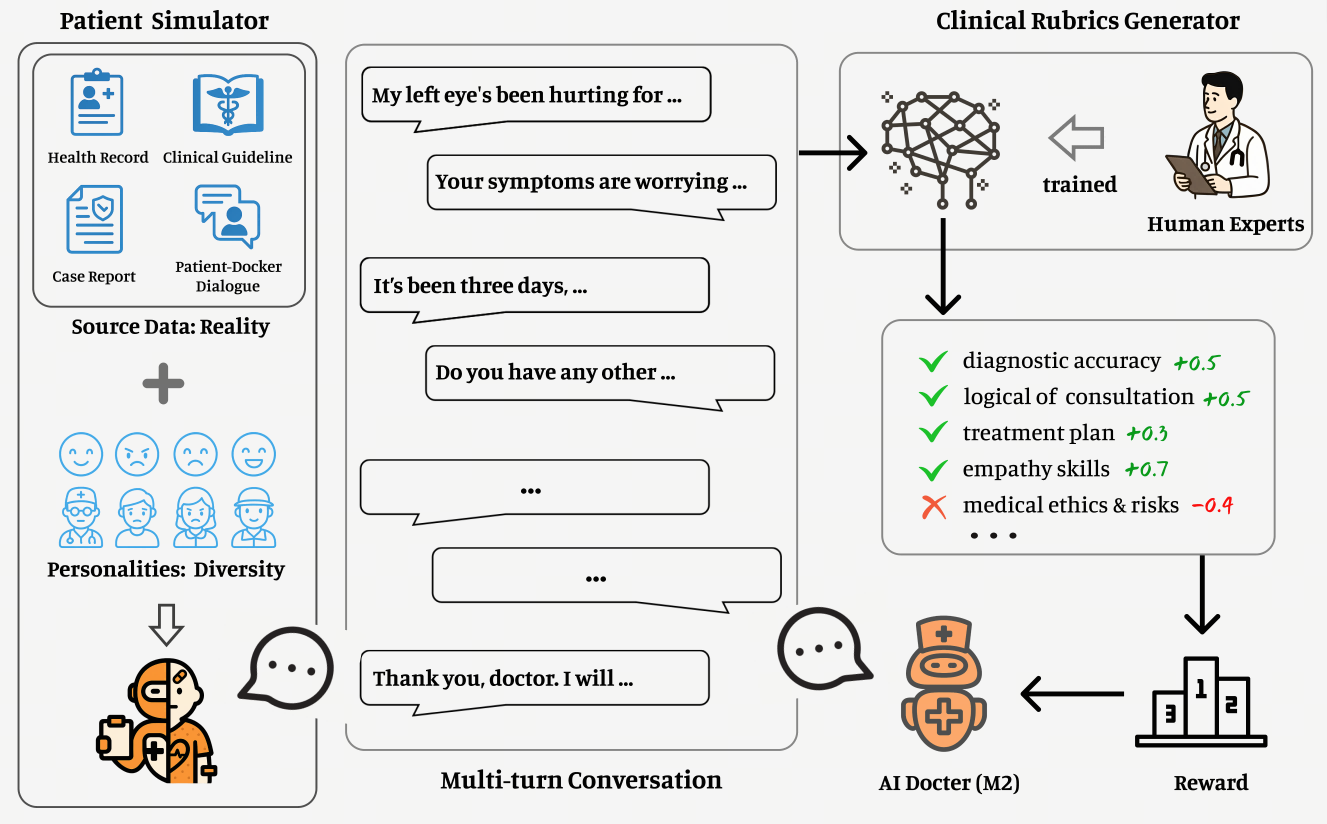
在強化學習的多輪對話中,AI患者與AI醫生快速生成數百萬條貼近真實的交互信息,驗證器充當裁判實時打分評估,根據打分結果模型策略動態優化,形成了一個具有規模化可監督信號的訓練閉環,讓訓練過程與效果如“飛輪”般效率倍增。
百川智能還構建了一個以天為頻率更新的權威醫學數據庫,涵蓋病例、論文、文獻、指南、藥學、生物學、合成數據等。為防止綜合能力退化,采用醫學數據、通用數據、數學推理數據2:2:1的比例,并引入領域自我約束訓練機制,確保模型是一個具有通識、推理等綜合能力的高水平醫生,避免成為只會醫學知識考試的高分低能者。
(更多技術創新點詳見https://www.baichuan-ai.com/blog/baichuan-M2)
這些技術探索與創新,不僅為醫療能力提升開創了全新路徑,也為通用大模型強化學習提供了新思路新方法。
在中國臨床診療場景的問題評測中,對比gpt系列模型,Baichuan-M2展現出更明顯的可用性優勢。
百川從中國醫學指南對齊、醫療政策適配和患者需求洞察等多個維度進行了深度優化,中國醫療機構和醫生應用時,會明顯感受到這一區別。
中外患者人群特點不同、醫療服務資源與優勢有所差異。例如,肝細胞肝癌,中國以乙肝相關肝癌為主,西方更多是酒精或丙肝相關患者,不同類型患者的的手術風險不同;加上中國外科手術經驗豐富、手術期管理成熟,因此,在同一疾病遇到多種治療方案時,中西方指南對于優選哪種治療方案存在差異。
在一個具體的真實案例中,針對CNLC IIa期(BCLC B期)的肝細胞肝癌患者,Baichuan-M2首推在具備手術條件的情況下進行解剖性肝右葉切除手術(或根據腫瘤具體位置,可考慮擴大右半肝切除、右三葉切除等),目標是R0切除。在國家衛健委最新發布的《原發性肝癌診療指南》(2024版)中,肝切除術是潛在根治性治療,可提供最佳的長期生存獲益,Baichuan-M2嚴格遵循這一方案。
同一病癥gpt-oss-120b則建議首選經動脈化療栓塞術(TACE),理由是符合 BCLCB 期治療指南。

臨床醫學專家認為,類似的情況還有很多。僅就這個案例來說,手術切除或TACE都是可選方案,只是中西方指南不同,不是醫學上的高下之分,而是基于本地患者特點、醫療資源與當前醫學發展水平權衡之下的最優解。
醫療大模型能否將全球醫學知識、醫學證據轉化為符合本地優勢特長的臨床決策,也是為醫生和患者提供切實服務能力的關鍵,Baichuan-M2為此所做的專門優化,讓中國臨床場景有了專屬的頂尖模型。
今年2月,以Baichuan-M1為底座的AI兒科醫生在國家兒童醫學中心多學科會診中大放異彩,獲得會診專家一致認可。M2在醫療溝通、診斷合理、檢查合理、醫療治療、醫療安全六個維度相較于M1均顯著提升。
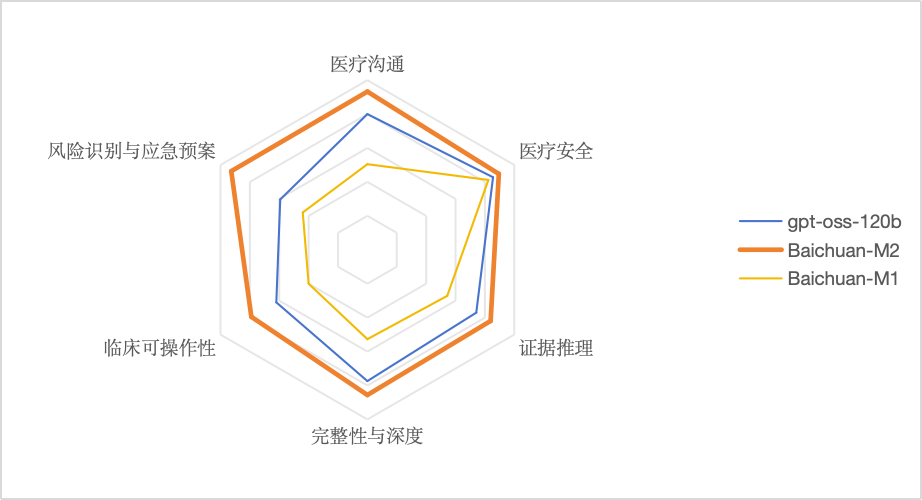
在北京市海淀區衛健委、北京大學第三醫院、國家兒童醫學中心等合作伙伴的支持下,M2在真實病例實測中體現出超強能力。
一位51歲女士近兩個月睡眠充足依感困倦、疲憊,脖子輕微腫脹。M2根據醫患對話,詳細梳理出持續性疲勞、體重增加等多個支持診斷的關鍵癥狀,綜合考慮患者用藥史、年齡、合并癥狀等因素,精準診斷出患者最可能病因為甲狀腺功能減退癥。
內分泌科專家表示,M2在關鍵征象基礎上提出首選假設(自身免疫性甲狀腺炎)并列出直接佐證、反證,之后給出條理化的鑒別診斷的推理方式,屬于典型的臨床思維流程,符合臨床醫學中公認的SOAP分析方式(Subjective主觀資料、Objective客觀資料、Assessment評估、Plan計劃)。它所采用的“支持 / 不支持”兩欄逐一比對的方式也符合住院醫師寫病程記錄時常用的思路,最后給出進一步檢查與管理建議,充分體現出“閉環思維”。
醫院之前部署的其他模型,知識問答上表現不錯,但沒有這么專業的主任醫師級專家思維,M2模型展現出人類高水平專家的思維方法讓醫生們驚嘆。
在另一真實案例中,一位15歲的小男孩莫名其妙咳嗽2個月,逐漸出現呼吸困難,吃了頭孢沒有好轉,急診時已經“重癥肺炎、心包積液”。醫生將患兒的病歷作為輸入與M2進行了診斷方面的討論。
M2全面復盤小男孩的病情,逐條引用CT、支氣管鏡、血氣分析等數據進行推理,準確鎖定“支氣管內占位”主因,主動給出氧療、抗菌/抗病毒劑量區間等極具執行性的治療意見。
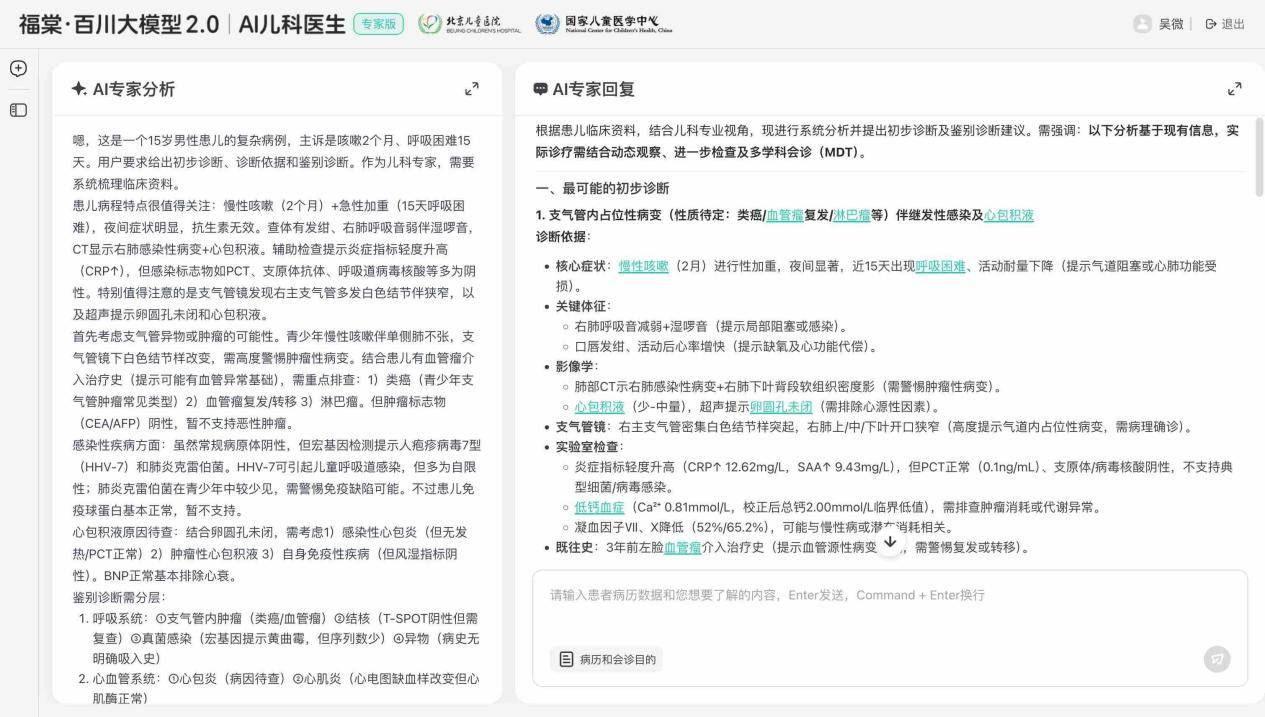
國家兒童醫學中心專家認為,M2在醫學正確性、證據鏈推理、可操作性上展現出極強的專業性,在風險預警方面的表現可圈可點,關注到患兒有呼吸衰竭、心包填塞等風險,并給出應急方案。此外,它還將患兒既往血管瘤與當前病變聯系,為醫生打開了更廣闊的思路。
本文被轉載1次
首發媒體 | 轉發媒體
| 轉發媒體






